FAIR data: come fare di più? AKA: devo re-imparare l'Italiano
In preparazione alla giornata Open Data 2020 (7 Marzo), e in concomitanza con l'Open Data Sicilia raduno (che poi purtroppo è saltato), mi sono fermata a riflettere (ancora una volta) sull'importanza di dati aperti per la ricerca scientifica e sull'eleganza e bellezza dei principi FAIR.
In questo post vorrei:
- ricordare perché i dati aperti/FAIR per la ricerca scientifica non sono un'opzione, ma un vero e proprio must-have
- evidenziare i punti chiave nel costruire una strategia che punti all'implementazione di principi FAIR all'interno di una comunità di ricerca (indipendentemente dal settore/disciplina)
- fornire un esempio concreto di suddetta implementazione
- ricordarmi come si scrive in Italiano e iniziare finalmente un po' di sostegno e diffusione per la scienza aperta nella mia madrelingua
Let's go!
Vorrei partire dall'evidenziare un privilegio di grandissima portata per noi ricercatori del 21esimo secolo: grazie alle tecnologie e alle risorse di cui oggi disponiamo, possiamo navigare in un mare sconfinato di dati, alla ricerca di fenomeni (più o meno ordinati) che talora non solo non riusciamo ad osservare, ma che non sono nemmeno contemplati dalla teoria.
 |
| Il quarto paradigma della Scienza: eScience, data-driven science, data-intensive science. Insomma, un mare di dati. [Immagine creata da Paola Masuzzo e distribuita con licenza CC-BY] |
Rimane da capire, ahimè, perché l'attuale economia di valutazione accademica rimanga così incentrata sull'idea arcaica del 'paper', del tutto statico e inadeguato a rappresentare la complessità della produzione scientifica dei nostri giorni. Ma questo è un altro discorso (o no?!).
La domanda alla quale vorrei provare a rispondere in questo post è - come navighiamo in questo mare di dati, senza rischiare di morire annegati? (sì, un po' drammatico come tono, lo ammetto, ma non ho resistito alla rima). Quali sono cioè gli strumenti che ci aiutano a trovare i dati che stiamo cercando sul web, ad interpretarli correttamente (che non è banale), e poi, volendo, anche a riutilizzarli?

Questo post non è il luogo adatto per una vera e propria lezione sui principi FAIR, ma vorrei quantomeno elencarli e ricordare a chi legge di cosa stiamo parlando.
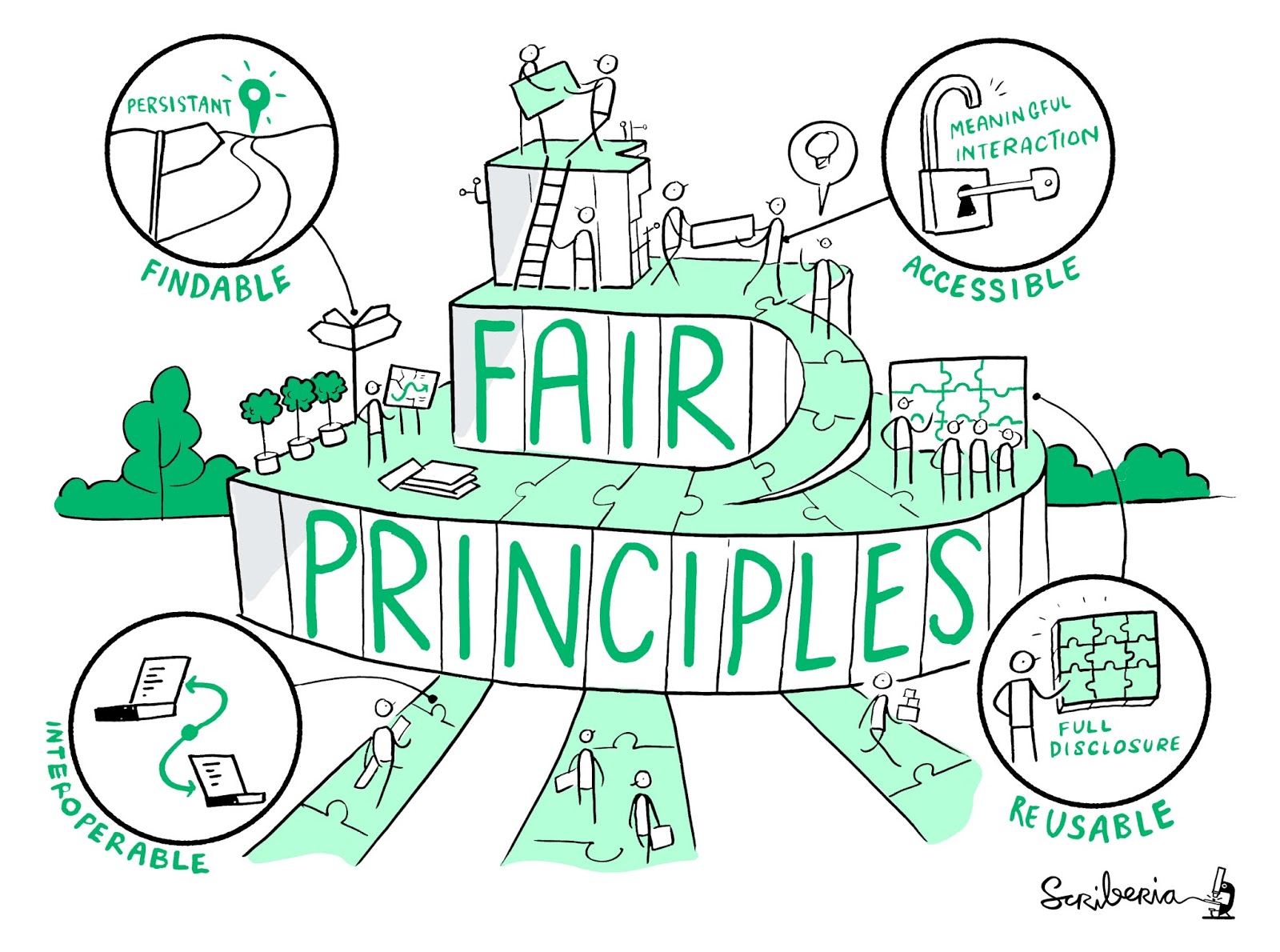 |
| I principi FAIR. [Immagine creata da Scriberia per 'The Turing Way community' e usata con licenza CC-BY | The Turing Way Community, & Scriberia. (2019, July 11). Illustrations from the Turing Way book dashes. Zenodo] |
- F = FINDABLE: so come trovare i dati (i dati sono identificati attraverso metadati e identificativi univoci e persistenti)
- A = ACCESSIBLE: so come accedere ai dati (questo non implica che i dati siano aperti, ma implica che siano resi chiari i metodi per arrivare ai dati e scaricarli)
- I = INTEROPERABLE: riesco ancora ad usare i dati anche se cambio computer o software (i dati sono salvati in formati non proprietari, non compressi, non criptati, con standard documentati)
- R = REUSABLE: so se e come posso riutilizzare i dati (la licenza d'uso è chiara)
Quando i principi FAIR sono stati introdotti alla comunità scientifica per la prima volta era il 2016, l'articolo lo trovate qui. Per dirla un po' alla "hype cycle" (nonostante i principi FAIR non siano una tecnologia, ma anzi del tutto indipendenti da implementazioni tecniche), in questi quattro anni che sono trascorsi si è assistito ad un'onda iniziale di entusiasmo, seguita da una valle di lacrime (quando ci siamo tutti resi conto che implementare FAIR data non è proprio banale), e infine un'illuminazione miracolosa che ci ha spinti fuori dalla valle di lacrime e ci ha portati finalmente a produrre, produrre, produrre. Qual è stata l'illuminazione miracolosa? Capire che, come per tutti i (più o meno grandi) cambiamenti da attuare nel mondo della ricerca, bisogna partire dalle comunità (ho parlato un po' di questo aspetto nell'ambito più generale della scienza aperta in questo post).
E proprio partendo dalla comunità (dai ricercatori, dal loro modo di fare ricerca e produrre dati, dalle loro esigenze computazionali, pratiche, teoriche...), abbiamo ideato e sviluppato i primi prodotti di standardizzazione per dati di migrazione cellulare FAIR (sì, dati che descrivono e ci fanno capire come si muovono le cellule).
 |
| Uno studio di migrazione cellulare con i prodotti di standardizzazione (in alto) adattati, estesi o ideati per ogni unità funzionale dello studio. [Immagine creata da Paola Masuzzo e distribuita con licenza CC-BY] |
Questo articolo spiega nel dettaglio i prodotti illustrati sopra. Quel che mi preme sottolineare in questo post è una lezione importantissima che ho imparato durante quello che è stato un faticoso percorso durato qualche anno e che ha portato alla proposta di questi prodotti di standardizzazione.
Questa lezione è fatta di alcuni punti, che riporto qui in ordine sparso:
- bisogna chiedere ai ricercatori: che dati producono? Come li producono? Con quali software? Costruire un catalogo di 'reference datasets' aiuta moltissimo a progettare degli standard che siano allineati con la realtà delle cose (e che quindi siano poi più facilmente adoperati dalla comunità stessa)
- quando si vogliono creare degli standard per una 'nuova' disciplina, non serve reinventare la ruota: molto probabilmente ci sono già moltissime risorse a disposizione e assolutamente pronte ad essere usate, o adattate ed estese, qualora questo fosse necessario
- è indispensabile creare strumenti per rendere il tutto quanto più semplice possibile (make it easy è la regola d'oro): ad esempio, se si propone un nuovo formato di file standard per far sì che i dati siano interoperabili, è necessario sviluppare un'API, un pacchetto software, una qualunque cosa, perché i ricercatori siano in grado di convertire i loro formati del cuore al formato standard in questione
- non arrendersi mai. Ascoltare le esigenze della comunità di ricerca vuol dire anche andare incontro ad una serie (talvolta lunghissima) di iterazioni per cui le specifiche per uno standard continuano a cambiare, o una checklist per un report non è informativa abbastanza o lo è fin troppo... si progettano degli standard, si chiede ad un piccolo team di provarli, ci si rende conto che gli standard non sono ancora ottimali, e si ricomincia. Alla fine, però, se funziona, è una grande soddisfazione.
~pcmasuzzo


Comments
Post a Comment